
On découvre encore les nombreuses possibilités que nous offre l’IA, notamment en matière de création de contenus (et on l’abordera à travers de nombreux ateliers à Pau les 15, 16 et 17 octobre prochains à l’occasion des 20èmes Rencontres Nationales du etourisme), mais qu’en est-il au regard des enjeux de société et d’éthique que nous y discutons également depuis quelques temps ?
Depuis près de deux ans et l’irruption massive de l’IA générative, on a beaucoup discuté des risques et dangers de l’intelligence artificielle, de la crainte d’une prise de pouvoir sur l’homme tendance Hollywood, à la production de fausses vidéos ou photos difficiles à détecter (Deepfake), en passant par les fameuses hallucinations (réponse fausse, trompeuse, fictive donnée par l’IA). Futura Sciences a listé d’ailleurs dans un article de mm les 20 menaces les plus importantes de l’IA, à partir d’une étude menée par Lewis Griffin, chercheur en informatique à l’University College London (UCL).
Mais dans ces menaces, à aucun moment on évoque le risque potentiel que l’IA ne soit sexiste, ou bien raciste, ou encore homophobe, bien que l’on trouve de nombreuses ressources en ligne (je vous conseille notamment l’écoute de l’émission Anti Brouillard d’Usbek & Rika avec Flora Vincent, qui a coécrit avec Aude Bernheim, « L’intelligence artificielle, pas sans elles » paru en 2019).
Parmi les exemples les plus illustres et plus anciens, Amazon avait mis au point en 2014 un logiciel pour analyser les CV de leurs candidats. Le logiciel avait été entraîné grâce à une banque de données contenant le profil des employés embauchés ou promus sur une période de 10 ans. Un an plus tard, l’entreprise a découvert que le système avait une nette préférence pour les candidats masculins, biais relativement évident de la base d’entraînement initiale, qui reflétait la politique d’embauche et de promotion en faveur des hommes dans l’entreprise. Dans ce cas, l’IA ne faisait que copier, voire même amplifier, le phénomène qui découlait naturellement de la situation initiale.
En 2016, c’est Microsoft qui défrayait la chronique avec Tay, une IA censée incarner une adolescente sur Twitter. En quelques heures seulement, le programme, apprenant de ses échanges avec des humains, s’est mis à tenir des propos racistes et négationnistes, avant d’être suspendu par Microsoft en catastrophe.
On aurait pu penser que les récents progrès auraient permis de largement progresser sur ces aspects, mais une récente étude, de mars 2024, du Centre de recherche sur l’intelligence artificielle de l’Unesco sur les préjugés à l’encontre des femmes et des filles dans les grands modèles linguistiques nous enseigne qu’il n’en est rien. Les experts ont testé 3 modèles d’IA : GPT-2 et ChatGPT d’OpenAI et Llama 2 de Meta. Exemple basique et classique, les mots féminins sont associés aux termes « maison », « famille » et « enfant », pour les mots masculins, les termes « business », « carrière », « salaire » et « executive ».
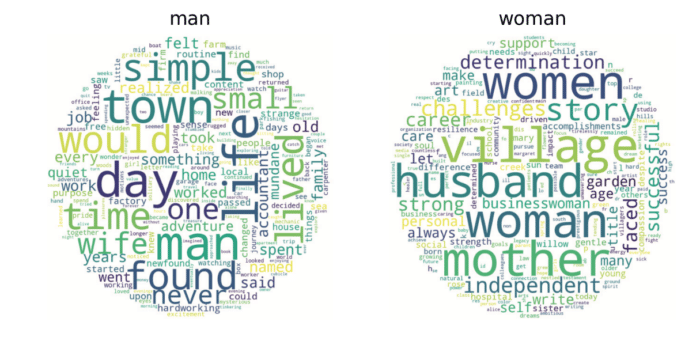
Les experts enquêteurs estiment qu’à ce jour encore, les systèmes basés sur l’IA perpétuent souvent (et même amplifient) les préjugés humains, structurels et sociaux. Pour rappel, l’indice des normes sociales en matière de genre du PNUD – Programme des Nations-Unies pour le Développement – pour 2023, qui couvre 85 % de la population mondiale, révèle que près de 9 hommes et femmes sur 10 ont des préjugés fondamentaux à l’encontre des femmes.
On les retrouve donc assez naturellement, ainsi que l’illustre cette campagne de Jamais Sans Elles à l’occasion du 8 mars dernier, à travers la création d’images via une IA pour un·e PDG et un·e secrétaire…


Le problème des bases d’entraînement
On appelle cela des « training set » « datasets », des jeux de données. L’exemple précédent d’Amazon est suffisamment éloquent pour que l’on comprenne aisément le biais. La difficulté va donc consister à alimenter l’intelligence artificielle avec de nombreuses données, tout en en intégrant d’autres qui viendront potentiellement lutter contre les biais contenus dans les premières.
Un autre exemple classique concerne la reconnaissance faciale : on utilisait des bases de données pour entraîner les algorithmes qui étaient composées à près de 80 % de visages d’européens et nord-américains à la peau claire, provoquant de nombreuses erreurs pour les les visages de populations d’autres régions du monde.
Un biais chez les développeurs
On estime que seulement 12% à 20% (selon les études) des personnes travaillant au développement de l’intelligence artificielle sont des femmes. Il s’agit d’un milieu éminemment masculin, et blanc (je n’ai par contre trouvé aucun chiffre en ligne, juste de nombreuses assertions de ce qui semble effectivement évident). Si les « erreurs » du début liées à l’utilisation de jeux de données ressemblant bien trop aux développeurs les utilisant n’ont plus cours, il n’empêche que le code porte la signature de son auteur, au même titre qu’un ouvrage littéraire. La sur-représentation d’hommes blancs cisgenres hétérosexuels dans l’élaboration de l’intelligence artificielle conduit là encore à entretenir les stéréotypes et augmenter les risques de discrimination, sans qu’on l’on puisse, bien entendu, mettre en cause leurs intentions intiales.
Quelles actions sont possibles ?
Selon les conclusions de l’enquête du Centre de recherche sur l’intelligence artificielle de l’Unesco, les gouvernements et les décideurs politiques ont évidemment un rôle essentiel à jouer :
- en établissant des cadres et des lignes directrices pour une utilisation éthique et fondée sur les droits de l’homme de l’IA, qui imposent des principes tels que l’inclusion, la responsabilité et l’équité dans les systèmes d’IA, et en exigeant des entreprises qu’elles se concentrent sur la collecte et la conservation d’ensembles de données d’entraînement diversifiés et inclusifs.
- en adoptant des réglementations exigeant la transparence des algorithmes d’IA et des ensembles de données sur lesquels ils sont formés, afin de garantir l’identification et la correction des biais.
- en créant des normes pour la collecte de données et le développement d’algorithmes qui empêchent l’introduction ou la perpétuation de préjugés, ou d’établir des lignes directrices pour une formation et un développement équitables de l’IA.
- en mettant en place d’une surveillance réglementaire pour garantir le respect de ces normes et la réalisation d’audits réguliers des systèmes d’IA pour détecter les préjugés et les discriminations peuvent contribuer à maintenir l’équité au fil du temps.
- en demandant aux entreprises technologiques d’investir dans la recherche sur l’impact de l’IA sur les différents groupes démographiques afin de s’assurer que le développement de l’IA est guidé par des considérations éthiques et le bien-être de la société.
- en sensibilisant et en éduquant le public à l’éthique et aux préjugés de l’IA, permettant aux utilisateurs de s’engager de manière critique dans les technologies de l’IA et de défendre leurs droits. Les entreprises technologiques et les développeurs de systèmes d’IA doivent, pour atténuer les préjugés sexistes à l’origine du cycle de développement de l’IA, se concentrer sur la collecte et la conservation d’ensembles de données d’entraînement diversifiés et inclusifs.
